


������̳ R&D have been carrying out research in the area of IP production for a number of years. Over that time we have developed many and libraries in order to prototype techniques, further develop our understanding and implement emerging standards.
In order to aid this work, we make heavy use of continuous integration, along with a number of tools to aid with continuous delivery of our software. In this post, we’d like to provide a little insight into some of the tools and techniques we've relied on over the years.

Background
As the broadcast industry makes the gradual transition from a dependence on fixed function hardware to flexible software-defined architectures, a number of new challenges present themselves.
A typical production centre may undergo a re-fit or technical refresh once every few years, with only minor upgrades and capacity increases performed in the intervening period. By comparison, the infrastructure used by a cloud service may routinely be completely re-deployed in cycles measured in hours or days.
As we create systems to investigate the production centre of the future, it's important to adopt and demonstrate that they can be applied to a broadcast media environment. A large part of this work involves building ever-larger experimental production facilities using on-premise and public cloud infrastructure. The rest of this post talks about some of the tooling we're using to help us do this.
Continuous Integration & Jenkins
Since the early days of our IP production work, we have used continuous integration in order to assist our development effort, and to ease our deployment to a range of hosts used to test out our work. Our codebase started off using primarily C and , but has progressed to include other languages including and . Each of these poses a different set of challenges for development, build, test and deployment.
is a continuous integration tool we have used to attack these problems, and helps us in a number of ways; First, software is tested to ensure it is written in a clean style (linting), compiles and that any unit tests it includes pass. Second, software is packaged for deployment using (to create packages) and (to create RPM packages).
Each of these tasks is relatively straightforward for an individual software repository, but when projects consist of multiple chained dependencies this can become significantly more complex.
We now make use of pipelines to manage some of this complexity. With this approach we can clearly define, and version control, the stages in our build process. We’ve used a feature called , which enables us to re-use common tasks across a range of pipelines, extensively as part of this work.
Using Software Packages to Build a System
Jenkins delivers our software in the form of lots of small packages. The next step towards building a software-defined broadcast system is to get each of these packages installed in the right places, with the right configuration.
We use (a configuration management tool) to solve this problem. Ansible lets us write down our configuration in a structured manner, and apply it quickly, frequently and automatically to a wide range of systems (such as bare-metal servers, containers, virtual machines). We’re even using Ansible to deploy and configure our Jenkins slaves!
An important feature of Ansible is that it lets us parameterise our configuration so that a template can be easily reused across a range of host environments.
Moving to the C���dzܻ�…
Our current work in the cloud brings new challenges. Here, even the infrastructure itself can be defined using software (for example network configuration).
We use (an infrastructure-as-code tool) to help us build infrastructure, and then re-use some of our continuous integration and Ansible tooling to help us build and deploy our software on top of this. In combination, these tools help us move quickly, repeatably and reliably.
Example: Building a Software System in the Cloud
The diagram below shows how some of these tools come together to run our cloud systems, such as our experimental Media Object Store (Squirrel); built using Python and a variety of managed cloud services.
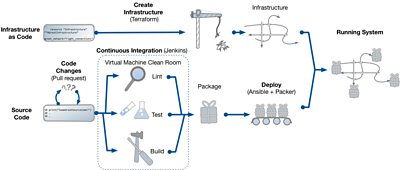
The deployment process begins with running continuous integration tests whenever new code is submitted; we do this for all proposed changes in . As part of this process, a virtual machine is provisioned using the project’s dependencies, and used as a clean-room testing environment. Once a change has been reviewed and approved, it is merged and the software package rebuilt and made ready for deployment.
For our cloud deployments, it is important that we take a snapshot of all our dependencies, so if we deploy more hosts (for example to increase capacity) we can guarantee the same code is running. It also becomes very easy to roll back to a known-good state, just redeploy the same artifact from the archive. We do this using to make a relocatable ; although use the to achieve something similar.
Along with a package to deploy, we need somewhere to deploy it; this is where Terraform comes in. Terraform compares the current infrastructure (compute instances, load balancers, DNS records, databases etc.) to configuration held in source control, and makes any necessary changes. Along with Terraform, we also use and Ansible to create “base images” for each of our services; containing some core software such as Python itself, along with HTTPS termination and authentication. These base images are built from the same automation as the Vagrant box used to run the tests; so we know that if the tests pass, the deployment should work.
The last step in the process is to deploy the package onto the infrastructure (remember the base image doesn’t contain our code). Ansible is run on the deployment system to download the PEX file, write out some configuration and restart services if needed. When new instances come online, they run the same Ansible playbook to configure themselves as well, so all instances end up looking exactly the same. Also, if the infrastructure and base image haven’t changed (a very common case), we can re-use existing instances and just replace the software, reducing deployment time from several minutes to around one.
Overall, this deployment process serves us well, allowing us to iterate quickly on our experiments. Using Terraform also means we can use managed services from a wide variety of providers, indeed one of our goals is to have the flexibility to use various public cloud providers or - a challenge for the future.
Aiming for the Software-Defined Production Centre
So, to re-cap, our overall aim is to bring modern software engineering practices to all aspects of the broadcast chain: not just every piece of software, but also the infrastructure itself.
Using techniques such as continuous integration, automatic testing and configuration management gives us much more confidence that our systems will work correctly, meaning we can build much more agile production systems which can be quickly adapted and changed.
- -
- ������̳ R&D - High Speed Networking: Open Sourcing our Kernel Bypass Work
- ������̳ R&D - Beyond Streams and Files - Storing Frames in the Cloud
- ������̳ R&D - IP Studio
- ������̳ R&D - IP Studio: Lightweight Live
- ������̳ R&D - IP Studio: 2017 in Review - 2016 in Review
- ������̳ R&D - IP Studio Update: Partners and Video Production in the Cloud
- ������̳ R&D - Running an IP Studio
- ������̳ R&D - Building a Live Television Video Mixing Application for the Browser
- ������̳ R&D - Nearly Live Production
- ������̳ R&D - Discovery and Registration in IP Studio
- ������̳ R&D - Media Synchronisation in the IP Studio
- ������̳ R&D - Industry Workshop on Professional Networked Media
- ������̳ R&D - The IP Studio
- ������̳ R&D - IP Studio at the UK Network Operators Forum
- ������̳ R&D - Industry Workshop on Professional Networked Media
- ������̳ R&D - Covering the Glasgow 2014 Commonwealth Games using IP Studio
- ������̳ R&D - Investigating the IP future for ������̳ Northern Ireland
-

Automated Production and Media Management section
This project is part of the Automated Production and Media Management section