Programme Segments API - discovering what ������̳ programmes are made of

James Callender
Product Manager
Tagged with:
The wealth and breadth of ������̳ content that’s available at any given time is staggering and it’s often difficult to find exactly what you’re looking for. James Callender, Product Manager in the ������̳ Platform team, talks about the ways in which Programme Segments API will make that search easier. He introduces the API and explains what it is, what it enables and outlines plans for its future.
Firstly, what are segments?
Segments are metadata used to define a specific part of a programme. Currently we have four types; music, chapter, speech and highlight.
Music segments are used to define where a music track was played within a programme along with some descriptive metadata such as artist name and track title.
Chapter segments are used to define a distinct part of a programme, news items within a news bulletin are a good example.
Speech segments are used to define a particular piece of speech that’s of interest, an example could be a piece of poetry from your favourite radio programme.
Highlight segments are used to mark a point of interest in a programme, the examples that spring to mind for a lot of people are goals in football matches and points in tennis matches.
At the moment we have around 3.3 million segments in our dataset, growing at a rate of around 1100 per day. Music segments are by far the biggest proportion, making up 96% of it.
What is the Programme Segments API?
The Programme Segments API makes these segments discoverable to our websites and apps. The API is based on a architecture pattern, it uses hypermedia to enable developers to easily discover what they need and also features filters, sorts and various “mixins” which allow decoration with other relevant metadata. This choice of architecture makes it easier for us to create multiple, targeted endpoints in the future for other specific use cases. If you would like to know more about this topic take a look at this recent by my colleague Iain.
Segment metadata is written to the API in one of two ways. The first is via content management tools used by our editorial teams to manually type in segment metadata relevant to a programme they are working on. The second is via components built to automatically generate metadata...more on that later.
What does segment metadata enable?
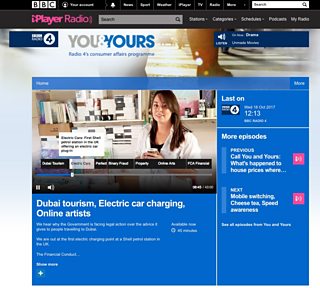
At the moment music segments are used to power “now playing” features so that listeners of radio programmes can see the artist name and track title of music currently playing on the radio show they are listening to. It’s also used to allow listeners to go back and look at track listings for shows they enjoyed or shows they missed - take a look at this recent show for an example.
������̳ Music’s Find a track service can help you find a track that you previously heard playing on the radio as long as you know roughly when it was that you heard it. Another great example of a service powered by music segment metadata.
If you came to the ������̳ to watch Wimbledon online last summer you might have noticed markers on the playback bar. Those markers were powered by highlight segments defining interesting moments in the matches such as set point, match point and championship point.
There’s also chapter segments, which allow listeners or viewers to navigate back and forth through programmes e.g. jumping to the start of a topic they found interesting. Take a look at the Radio 4 programmes and as they often have chapters.
In the future segments could become an everyday feature of ������̳ products and services. One of the ������̳’s top priorities is to offer personalised experiences online, and a richer set of segment metadata could support features such as granular recommendations about programmes we think our audience might be interested in. For example, as a signed in user of the ������̳, we might know that you read a lot of articles about self-driving cars. In the event that a radio or TV programme is broadcast with a particular chapter on that topic then we could recommend that exact chapter to you; jumping you straight to the point in the show where the topic starts.
In the world of news, segmenting our news programmes could enable us to present you with a personalised news bulletin, with easy access to the news stories that are relevant and of interest to you. Recently our team have been exploring voice interfaces. Segments are key to enabling users of voice interfaces to skip to the next news story or restart the one they were just listening to. You can read more on the News Labs project .
Content navigation could be further improved to allow you to skip to the next highlight, restart the current scene or skip programme recaps or credits whilst binge-watching.
We could also make it possible for segments to be shared easily. You might come across a particular chapter of a programme or sports highlight you think a friend might be interested in watching and wish to share it via social media.
These are all examples of what segments could enable with further analysis, research and cross-������̳ collaboration. Here we’re only scratching the surface, there’s a whole number of new and exciting features segments could enable and we’re just getting started.
Generating metadata via automation
Only 7.3% of the 4 million plus programmes stored in our database since 2007 have segments. Enabling some of the use cases I’ve described will require us to massively scale our segments dataset, further refine segment types and improve the quality of the data. That means adding new types of segments such as weather update, travel update, quiz, interview and so on. It also means adding segments to more of the programmes we produce.
Tackling this isn’t something we can do with human power alone. We simply don’t have, and are unlikely to ever have, enough editorial staff to be able to manually create segments for each and every programme, therefore automatically generating segment metadata must be part of our solution.
In fact, we are already generating our music segment metadata automatically. Quite a number of our radio networks use a digital music playout system. Every time a track starts to play the system generates a message that includes now playing information (artist, track title, record label, duration, start time etc). The message is sent to a software component which matches that artist information with artist information stored in the database for further enhancement. The enhanced message is then processed and matched to programme schedule information and finally written to the database behind our API as a music segment.
For TV programmes on ������̳ One, ������̳ Two & ������̳ Four we use 3rd party acoustic fingerprinting technology to determine the music tracks played. The metadata generated via the acoustic fingerprinting component is also sent to the same software component mentioned previously in order to generate music segments, again writing them to our database.
Aside from playout systems and acoustic fingerprinting, there’s a whole host of other potential data sources available to us from sports data feeds to programme running orders, subtitles, transcripts and analysis of the video and audio assets we produce.
Although there’s a lot of data available to us, turning it into well defined segment metadata that’s useful on our websites and apps is quite a challenge. Generally the problem can be broken down into two parts;
- Determining where a segment is within a programme (where it starts and ends)
- Generating descriptive metadata about that segment
Sports data feeds and running orders tend to be a pretty good source of data for determining where segments start and end. Taking sports data feeds as an example, in a recent hack day we built a prototype application that determines the start and end of a highlight segment for a goal scored in a football match. There’s a whole number of other different sports data feeds available that we could use in a similar way to generate highlight segments for a number of different sports programmes.
We are also looking to use to help us tackle both problems. In particular the areas of (NLP) and . An area of NLP called automatic speech recognition could be used to generate text transcripts from audio. Another area of NLP called summarisation, which generates readable summaries of arbitrary text preserving as much of the meaning as possible, could be used to generate titles and synopses for segments. The same could be done using subtitles where available.
Computer vision attempts to extract symbols from raw visual data, those symbols can be used to produce information. One particular area of computer vision that’s of interest to us is video feature analysis which can be used to annotate video with tags. We can then add tags to segments to make them more discoverable.
Luckily, we’re not the only people at the ������̳ interested in solving these problems so our work brings about plenty of opportunity for collaboration, experimentation and prototyping.
Final Thoughts
Understanding what our content is made up of is an important step towards enabling a more personalised ������̳ and enabling you to find exactly what you want from our content along with giving you the opportunity to discover something new or unexpected. There’s certainly a lot more work to do to reach our vision of the future but this work excites us and I’m looking forward to discussing new opportunities with my colleagues.