成人论坛 Research & Development are developing capabilities that help production teams monitor live streams from remote video cameras. This work has involved a series of technology trials with The Watches - a 成人论坛 production that tracks the changes in nature throughout the seasons - to assist in finding interesting activity captured by the remote wildlife cameras that are a big part of the show's appeal to audiences.
Within R&D, this has been a productive and efficient collaboration between two teams, with Cloud-fit Production Capabilities progressively improving the media management capabilities. These are provided as a suite of microservices to the Intelligent Production Tools team, who are focused on the analysis algorithms and the user experience of the tools.
The last update we posted about our involvement with this project was around a year ago, so lets go as we bring you up to date with recent developments!

In our initial solution developed as a quick fix for Autumnwatch 2020, stream ingest was achieved by embedding a code snippet provided by the Cloud-fit Production Capabilities team into the analysis system to receive each feed. Segments of video and audio from the stream were time-labelled and written to the time-addressable media store whilst supplying the time-labelled frames of video directly to the analysis process. Lilac components were developed by the Intelligent Production Tools team, while the turquoise components were the work of the Cloud-fit Production capabilities team.
For Autumnwatch 2021, we built a scalable stream ingest service, which provides an API to create and configure stream ingest endpoints on demand. Since ingest is now managed independently, the analysis system retrieves the media from the store as it arrives, using a Python library designed for the purpose. Media at the "live edge" is retrieved within 2 seconds of ingest. There are various optimisations that could be made to reduce this latency, but for this use case 2 seconds of delay is tolerable, so there was no need.
Through using the system in a real-world context, we quickly realised some of the other advantages of decoupling stream reception from the analysis system. Because the streams are recorded independently, the analysis process could be stopped and redeployed without missing anything important. This made tweaking the algorithms during the trial much less risky. Historical content could be re-analysed, and we could run multiple analysis processes simultaneously on the same content.
Pulling streamed content from the store in this way made it much easier to support analysis of the audio from each of the live camera feeds alongside the video analysis to detect undesirable audio that may make content non-compliant or otherwise unsuitable for broadcast.
Walk Out to Winter

Relatively few new features were added to the Cloudfit Production Capabilities for Winterwatch 2022 due to time constraints: Winterwatch followed hard on the heels of Autumnwatch, with Christmas and New Year in between.
Small tweaks included:
- Priority packaging of clips: this feature made it possible for manual packaging requests from the production team to jump the queue
- Support for HEVC video: this enhancement was deployed during the trial without downtime and used for feeds from some of the farther-flung locations where link bandwidth was harder to come by
One of the changes we made for Winterwatch 2022 was to configure our time addressable media store to which we ingest the streams, to use an on-premise, S3-compatible data store based on . In previous iterations we used AWS S3 for this purpose.
This time we wanted to investigate alternatives with different cost models, to improve our understanding of the factors that should be used to select solutions at different layers. We also wanted to validate the modular design of our software services deployed across public and private cloud infrastructure to create flexible, hybrid systems that can deliver the best of both worlds.
The use of AWS S3 involves zero capital investment, with charges for the number of requests to the service and charges for data that remains in storage, as well as charges for exporting data. On-premise storage minimises operational costs but requires strategic capital investment and in-house expertise.
'Squirrel' is the name we use for our time-addressable media store, which manages the storage of content as short segments of elemental media, and its selective retrieval specified by time ranges. The diagram below illustrates how we modified its deployment to run across AWS and on-premise infrastructure. It shows an exploded view of Squirrel Media Store internals. The Squirrel Service exposes an API that clients use to interact with the store. Media Segments are stored in an S3-compatible object store. Data that describes how the stored segments relate to the stream timeline, along with other technical metadata, are recorded in a separate Media Info Database.
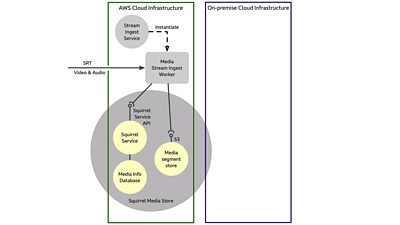
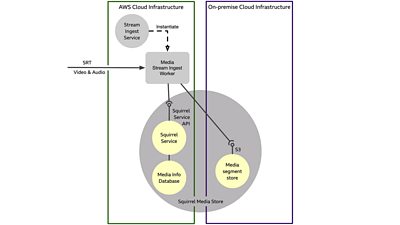
The Ceph storage can be accessed from anywhere using the HTTP-based object storage API, and S3-compatibility means it's relatively trivial for applications to switch between AWS-owned and on-premise storage.
Access to the stored media segments is achieved using pre-signed URLs issued by the Squirrel Service, whether the segment storage is AWS S3 or on-premise. This allows clients of the Squirrel API to access the content referenced by each URL without the need to share credentials giving blanket access to the storage bucket. Pre-signed URLs are valid only for a short time.
Internally, the Ceph object store is designed and configured for resilience. Three copies of each media segment are kept, each on different physical hardware. In this case, we're only using one Ceph instance but we could in principle add more storage instances on different sites, allowing cross-location replication to further enhance resilience.
Our deployment with stream ingest workers running on AWS infrastructure, putting media segments into on-premise storage, eliminates the cost of writing to AWS-S3 and the ongoing cost of storing the content for as long as it is required. However, this configuration incurs an extra dataOut cost per Gbyte to export the media segments from the ingest workers to the store outside the AWS ecosystem.
Future Work and Conclusions
Moving the stream ingest workers out of AWS onto on-premise compute resources co-located with the storage would be a worthwhile step to improve cost-effectiveness. There would be no dataOut cost in this configuration, as the media never enters the AWS ecosystem.
The R&D team who constructed our Ceph storage cluster have also built a co-located scaled instance of OpenStack that provides a platform to stand up the necessary virtualised infrastructure on demand, programmatically. We use to describe all of our infrastructure as code because of its ability to automate provisioning across multiple cloud infrastructure providers, so this change would be relatively straightforward, leading to something like the structure illustrated below.
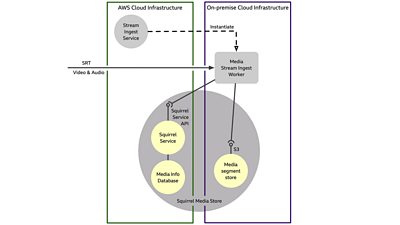
We'd also like to explore how feeding the insights gained from the various types of analysis performed on this media could be used to decide what we store and how long we keep it. If we put media in public object storage, we pay to use the space. If we create an on-premise object store for media, there is an up-front cost, which places a practical limit on its overall size.
Either way, we need to understand what value is associated with the content at any point in time, how frequently and how urgently we will need to access it. The data produced in these trials by the video and audio analysis and the list of regions for which clips were requested are just a few of many potential sources of information that could give us this insight and feed into automated decisions about media retention.
This work starts to provide real-world experience to allow us to compare the use of public cloud resources with on-premise infrastructure in a meaningful way. Their characteristics and cost models are suited to different usage patterns, but we don't have to choose one or the other for our entire deployment. Building from software services that can be operated across hybrid infrastructures lets us mix and match to create tailored deployments blending the benefits of both.
- - -
- -
- 成人论坛 R&D - Intelligent Video Production Tools
- 成人论坛 Winterwatch - Where birdwatching and artificial intelligence collide
- 成人论坛 World Service - Digital Planet: Springwatch machine learning systems
- 成人论坛 Springwatch | Autumnwatch | Winterwatch
- 成人论坛 R&D - Cloud-Fit Production Update: Ingesting Video 'as a Service'
- 成人论坛 R&D - Tooling Up: How to Build a Software-Defined Production Centre
- 成人论坛 R&D - Beyond Streams and Files - Storing Frames in the Cloud
- 成人论坛 R&D - IP Studio
- 成人论坛 R&D - IP Studio Update: Partners and Video Production in the Cloud
- 成人论坛 R&D - Running an IP Studio